
Mail.ru исправляется, и не перестаёт удивлять нас своей неистовой фантазией, на этот раз они придумали соревнование а-ля хайлоад. Дано ТЗ на написание несложного API, и возможность завернуть реализацию в Docker контейнер и запустить всё это под обстрел, но ресурсы ограничены, только 2 GB ОЗУ и 4 ядра, при этом RPS может достигать 1000. 1000 запросов в секунду Карл! Это значит что даже если удастся идеально распараллелить решение на 4 ядра, то ответ должен формироваться в среднем за 4 мс. При типичном времени ответа в ~100 мс для средненького Rails приложения это вызов. К тому же наличие статей типа Scaling Ruby Apps to 1000 Requests per Minute — A Beginner’s Guide (а это всего ~ 16 RPS) демотивирует уже на старте.
После нескольких экспериментов с PostgreSQL (который тоже надо запихать в это же контейнер), стало ясно что единственный путь — это не использовать внешние хранилища, а всё держать в памяти приложения. После ещё нескольких экспериментов, было решено выкинуть и Rails, что бы максимально обезжирить приложение.
Простые hello-world на Sinatra показывали больше 1к RPS, что выглядело весьма обнадёживающе и я начал прикидывать как поместить все данные в память, было видно что данные должны влезть, и на несколько хешей для индексирования должно было хватить. Но загружаемое решение падало на полном наборе данных.
Первый мой недочёт был в том что я считал все числа за 4 байта, но в 64-х битной системе это 8 байт.
Второй в том, что я совсем не учёл размер самих структур данных, ведь Ruby прежде всего для программиста, и потом уже для компьютера, он позволяет решать задачи быстро, он позволяет обуздывать бизнес логику своей динамической природой используя минимум кода и избегая копипасты, но за всё приходится платить. Я начал изучать что с памятью, оказалось что пустой массив и хеш занимают 40 байт, хеш с одним элементом 232 байта.
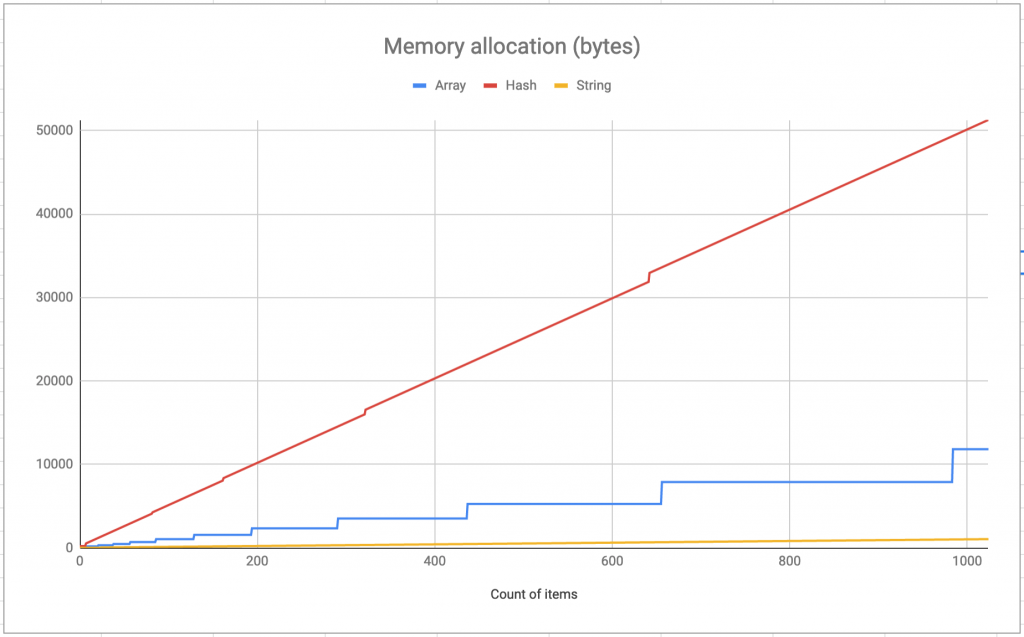
Здесь нужно учесть, чем я заполнял эти структуры, один символ строки здесь занимает 1 байт, массива 8 байт, в хеше ключ и значение 16 байт. Соответственно используя линейную регрессию получаем:
- Размер строки = кол-во символов + 40 байт
- Размер массива = кол-во элементов * 8 * 1.22
- Размер хеша = кол-во элементов * 16 * 3.15
Это верно для 1-байтных символов и 8-байтных ключей и значений.
1.22 и 3.15 — коэффициенты оверхеда. Т.е. простой массив с числами в среднем будет занимать в 1.22 раз больше памяти чем размер самих данных. Вот как это выглядит на больших размерах:

100 млн. элементов потребуют примерно 1 ГБ. памяти если сложить их в массив. На 100 млн. пар ключ-значение в хеш-таблице потребуется 5 ГБ ОЗУ.
Также я пробовал использовать Crystal, TruffleRuby, и даже новый JIT из 2.6, но всё это про оптимизацию CPU, Crysal вообще оказался однопоточным. В итоге Highload Cup я слил и сделал вывод что на данный момент Ruby не для хайлоада )