
Нет, это не фьючерсы с биржи, но тоже полезная вещь.
Постановка задачи
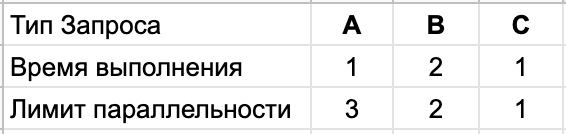
Допустим у нас есть сервер который может обрабатывать три типа запросов A, B и С. На каждый тип запроса сервер тратит определённое время, и на каждый из типов есть лимит параллельных запросов и если он превышен то сервер начинает отвечать очень медленно.
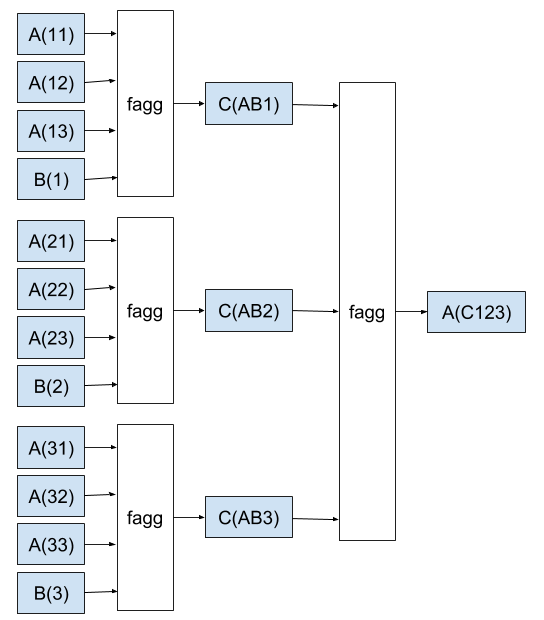
У этого сервера есть клиент который получает результат последовательно выполняя разные запросы, агрегирует результат, и снова выполняет запросы. По вот такому вот алгоритму

Блоки с белым фоном — это функции которые клиент считает сам, с голубым фоном — это внешние запросы к серверу.
Базовое решение
Самое наивное решение просто последовательно выполняет все запросы:
def a(value)
Faraday.get("https://localhost:9292/a?value=#{value}").body
end
def b(value)
puts "https://localhost:9292/b?value=#{value}"
Faraday.get("https://localhost:9292/b?value=#{value}").body
end
def c(value)
Faraday.get("https://localhost:9292/c?value=#{value}").body
end
a11 = a(11)
a12 = a(12)
a13 = a(13)
b1 = b(1)
ab1 = "#{collect_sorted([a11, a12, a13])}-#{b1}"
c1 = c(ab1)
a21 = a(21)
a22 = a(22)
a23 = a(23)
b2 = b(2)
ab2 = "#{collect_sorted([a21, a22, a23])}-#{b2}"
c2 = c(ab2)
a31 = a(31)
a32 = a(32)
a33 = a(33)
b3 = b(3)
ab3 = "#{collect_sorted([a31, a32, a33])}-#{b3}"
c3 = c(ab3)
c123 = collect_sorted([c1, c2, c3])
result = a(c123)
И выполняется оно чуть больше чем 19 секунд:
ruby client.rb 0.23s user 0.09s system 1% cpu 19.432 total
Распараллеливаем решение
Если посмотреть на алгоритм клиента, то можно заметить что часть запросов можно выполнить одновременно, но так как у сервера есть лимит то его нужно учитывать, чтобы это учесть можно нарисовать примерно такую схему:

Теперь можно использовать потоки чтобы это реализовать
a1 = [11, 12, 13].map { |v| Thread.new { a(v) } }
b1 = Thread.new { b(1) }
b2 = Thread.new { b(2) }
a1.each(&:join)
a2 = [21, 22, 23].map { |v| Thread.new { a(v) } }
a2.each(&:join)
a3 = [31, 32, 33].map { |v| Thread.new { a(v) } }
b1.join
b2.join
b3 = Thread.new { b(3) }
c1 = Thread.new do
ab1 = "#{collect_sorted(a1.map(&:value))}-#{b1.value}"
c(ab1)
end
a3.each(&:join)
c1.join
c2 = Thread.new do
ab2 = "#{collect_sorted(a2.map(&:value))}-#{b2.value}"
c(ab2)
end
b3.join
c2.join
c3 = Thread.new do
ab3 = "#{collect_sorted(a3.map(&:value))}-#{b3.value}"
c(ab3)
end
c3.join
c123 = collect_sorted([c1.value, c2.value, c3.value])
result = a(c123)
И это выполняется почти за теоретические 6 секунд
ruby client.rb 0.30s user 0.12s system 6% cpu 6.543 total
Но это решение слишком хрупкое, слишком легко допустить ошибку, к тому же если условия задачи изменятся, то придётся заново рисовать диаграмму и всё переделывать, это слишком накладно.
Решение с использованием Future из concurrent-ruby
Есть замечательная библиотека concurrent-ruby в которой есть много полезных и интересных вещей которыми мы так редко пользуется в обычной жизни. Future позволяет строить цепочки из зависимых друг от друга функций (всё как мы любим в функциональном программировании), при этом те фьючерсы которые в ожидании не жрут процессор и ничего не блокируют. FixedThreadPool может выполнять фьючерсы, при это позволяет задать максимальное количество параллельных потоков. Итого:
POOL_A = Concurrent::FixedThreadPool.new(3)
POOL_B = Concurrent::FixedThreadPool.new(2)
POOL_C = Concurrent::FixedThreadPool.new(1)
def a(value)
Concurrent::Promises.future_on(POOL_A) do
puts "Get A for #{value}"
Faraday.get("https://localhost:9292/a?value=#{value}").body
end
end
def b(value)
Concurrent::Promises.future_on(POOL_B) do
puts "Get B for #{value}"
Faraday.get("https://localhost:9292/b?value=#{value}").body
end
end
def c(value)
Concurrent::Promises.future_on(POOL_C) do
puts "Get C for #{value}"
Faraday.get("https://localhost:9292/c?value=#{value}").body
end
end
def ab(aa_feature, b_feature)
Concurrent::Promises.zip(b_feature, *aa_feature).then do |b, *aa|
c("#{collect_sorted(aa)}-#{b}")
end.flat
end
def collect_sorted(arr)
arr.sort.join('-')
end
aa1 = [11, 12, 13].map { |v| a(v) }
aa2 = [21, 22, 23].map { |v| a(v) }
aa3 = [31, 32, 33].map { |v| a(v) }
b1 = b(1)
b2 = b(2)
b3 = b(3)
c1 = ab(aa1, b1)
c2 = ab(aa2, b2)
c3 = ab(aa3, b3)
c123 = Concurrent::Promises.zip(c1, c2, c3).then do |*cc|
a(collect_sorted(cc))
end.flat
result = c123.value!
Получаем те же чуть больше 6 секунд
ruby client.rb 0.32s user 0.10s system 6% cpu 6.437 total
Но само решение гораздо более декларативное, достаточно задать алгоритм зависимости функций друг от друга и лимиты параллельности, и программа сама выполнится оптимальным образом! Полный код можно посмотреть здесь https://github.com/holyketzer/bonus-task-1. Конечно задача довольно сферическая, но хорошо позволяет понять концепцию futures и как их можно использовать с thread pool.